Matthew Lindfield Seager
This evening my son and I switched to Codenvy.com for his school project (he is building a quiz app).
It’s a bit more complicated to get going than repl.it and came with much older software versions but it seems to have a much higher ceiling and less weird constraints.
It feels similar to where Cloud9 used to be… before Amazon bought it and “AWSed” (complicated) it.
Today I finished going through the StimulusJS handbook and examples; stimulusjs.org/handbook/…
I haven’t used it in a proper Rails project yet but I’m sold on the principles.
I think I might need to learn ActionCable too though.
The good, the bad & the surprising of repl.it/languages/rails (after 2nd session with my 9 year old):
✅ WAY easier to get going than homebrew, rbenv, Ruby, bundler, Rails gems, etc
❎ Issues submitting forms due to invalid CSRF tokens
✳️ Database (SQLite) wasn’t persisted
“A setting in Safari is blocking Teams. In your browser, go to Preferences > Privacy and untick the Prevent cross-site tracking setting.”
Umm… No.

Two nice screenshot features in macOS 10.15/iOS 13:
- screenshot on Mac can show up on another device (e.g. iPad with Pencil). Edits on iPad reflected in real time on Mac
- get two screenshots using CarPlay, one of iPhone, one of car screen!
🤯 Modelling data (not behaviour) has been a huge part of my development work recently.
John Schoeman just made my brain explode (in a good way) demonstrating how a sprinkle of functional programming can totally simplify data processing: youtu.be/toSedSFnz…
Just watched another good RailsConf 2019 talk: Scalabale Observability for Rails Applications by John Feminella
Some really helpful advice on what to observe, how often and why to make sure an application is actually doing what we expect.
I went looking for a simple cloud based development environment for a project my son is working on and found repl.it/languages…
We’ve only kicked the tires so far but we had an empty Rails app up and running in seconds, not hours!
Micro.blog continues to steadily improve! I really appreciate how quickly Manton turned around some small improvements I suggested on Slack.
I’m also enjoying Byword for Markdown editing on iPhone, iPad and Mac. Link insertion (with link on the clipboard) is particularly slick!
Graphiti and Leverage
Episode 40 of Remote Ruby was so thought-provoking I added it back to my podcast queue.
After listening to it again my previous thoughts on Graphiti (at the end of that post) still stand. But something else jumped out at me this time…
Lee speaks passionately about Graphiti and Vandal enabling product owners or “business people” (I cringe at the label “non-technical”) to essentially explore the schema and see the relationships between data, much like they already do in Excel (or Business Intelligence tools).
It brings to mind what I wrote last night about the many levels of abstraction between one line in my Rails app and the hundreds of thousands of CPU operations that result.
There’s a huge productivity benefit to me not having to know much about CPU instructions, assembly language, C, virtual machines or abstract syntax trees just to query a database from a Rails app.
Similarly, I think there could be a huge productivity benefit if business people could examine existing queries to understand how their app works or point out logic flaws to the developers… or modify an existing query to extract some data without having to wait for a new API endpoint or report to be developed… or write a new query to demonstrate a product requirement or a feature they would like added.
Just like good developers work hard to understand the business they are supporting, I wonder if Graphiti and Vandal could be the lever that helps good business people better understand the app the developers are building.
The more I learn about programming, the more I discover how “inefficient” it can be…
While debugging my Rails apps I’ve noticed a single line of my code might cause dozens or even hundreds of other lines of Ruby code in various Rails gems to be executed.
Lately I’ve been learning that each of those hundreds of lines of Ruby has to be tokenised, then the tokens parsed into AST nodes and then the AST nodes compiled into YARV instructions. Each line of Ruby requires in 5-10 YARV instructions.
YARV is written mostly in C so each YARV instruction usually results in multiple lines of C code being run.
Each line of C then needs to be converted to assembly code for the current processor architecture.
The assembly code then gets converted to machine code, the actual instructions the CPU executes.
All that from a single line in my Rails app!
N.B. The deeper down the stack we go, the less confident I am of the details. I’m happy to be corrected if you notice I’ve got anything majorly wrong but don’t let technical details distract you from the main point :)
There are so many layers of “inefficiency” from the code’s perspective!!! And yet, even with all that conversion and compilation and manipulation, the result is usually displayed pretty much instantly the moment I press enter in the Rails console or hit “go” in my browser.
Each of those layers is like a carefully machined gear, multiplying the power of the layers above. The result is that we can write clear and readable Ruby code, mostly oblivious to the mountain of code we’re relying on to do the actual work of updating a database, responding to an HTTP request or performing a complex calculation.
To me the key takeaway (other than being grateful for all that hard work) is that I shouldn’t worry about the “efficiency” of my Ruby code, especially not to begin with. The computer can deal with an extra line of code, one more variable or an additional method call. Instead I should focus entirely on making my code easy to read, easy to reason about and easy to refactor. I need to improve the efficiency of my coding as a whole, not my code.
I’m reading Ruby Under a Microscope (http://patshaughnessy.net/ruby-under-a-microscope) 📖
2.5 chapters in and I’m astounded by just how much effort must have gone in to building Ruby over the years!
I’m very grateful that I can freely benefit from all that work!!!
Parsing vs Evaluating Order
Following up from my Ruby pop quiz the other day, I asked about the surprising behaviour on Stack Overflow.
Some commenters provided a little bit of help and then I did some more research. An answer to my own question is below.
Jay’s answer to a similar question linked to a section of the docs where it is explained:
The local variable is created when the parser encounters the assignment, not when the assignment occurs
There is a deeper analysis of this in the Ruby Hacking Guide (no section links available, search or scroll to the “Local Variable Definitions” section):
By the way, it is defined when “it appears”, this means it is defined even though it was not assigned. The initial value of a defined [but not yet assigned] variable is nil.
That answers the initial question but not how to learn more.
Jay and simonwo both suggested Ruby Under a Microscope by Pat Shaughnessy which I am keen to read.
Additionally, the rest of the Ruby Hacking Guide covers a lot of detail and actually examines the underlying C code. The Objects and Parser chapters were particularly relevant to the original question about variable assignment (not so much the Variables and constants chapter, it simply refers you back to the Objects chapter).
I also found, to see how the parser works, a useful tool is the Parser gem. Once it is installed (gem install parser) you can start to examine different bits of code to see what the parser is doing with them.
That gem also bundles the ruby-parse utility which lets you examine the way Ruby parses different snippets of code. The -E and -L options are most interesting to us and the -e option is necessary if we just want to process a fragment of Ruby such as foo = 'bar'. For example:
> ruby-parse -E -e "foo = 'bar'"
foo = 'bar'
^~~ tIDENTIFIER "foo" expr_cmdarg [0 <= cond] [0 <= cmdarg]
foo = 'bar'
^ tEQL "=" expr_beg [0 <= cond] [0 <= cmdarg]
foo = 'bar'
^~~~~ tSTRING "bar" expr_end [0 <= cond] [0 <= cmdarg]
foo = 'bar'
^ false "$eof" expr_end [0 <= cond] [0 <= cmdarg]
(lvasgn :foo
(str "bar"))
ruby-parse -L -e "foo = 'bar'"
s(:lvasgn, :foo,
s(:str, "bar"))
foo = 'bar'
~~~ name
~ operator
~~~~~~~~~~~ expression
s(:str, "bar")
foo = 'bar'
~ end
~ begin
~~~~~ expression
Both of the references linked to at the top highlight an edge case. The Ruby docs used the example p a if a = 0.zero? whlie the Ruby Hacking Guide used an equivalent example p(lvar) if lvar = true, both of which raise a NameError.
Sidenote: Remember = means assign, == means compare. The if foo = true construct in the edge case tells Ruby to check if the expression foo = true evaluates to true. In other words, it assigns the value true to foo and then checks if the result of that assignment is true (it will be). That’s easily confused with the far more common if foo == true which simply checks whether foo compares equally to true. Because the two are so easily confused, Ruby will issue a warning if we use the assignment operator in a conditional: warning: found `= literal' in conditional, should be ==.
Using the ruby-parse utility let’s compare the original example, foo = 'bar' if false, with that edge case, foo if foo = true:
> ruby-parse -L -e "foo = 'bar' if false"
s(:if,
s(:false),
s(:lvasgn, :foo,
s(:str, "bar")), nil)
foo = 'bar' if false
~~ keyword
~~~~~~~~~~~~~~~~~~~~ expression
s(:false)
foo = 'bar' if false
~~~~~ expression
s(:lvasgn, :foo,
s(:str, "bar"))
foo = 'bar' if false # Line 13
~~~ name # <-- `foo` is a name
~ operator
~~~~~~~~~~~ expression
s(:str, "bar")
foo = 'bar' if false
~ end
~ begin
~~~~~ expression
As you can see above on lines 13 and 14 of the output, in the original example foo is a name (that is, a variable).
> ruby-parse -L -e "foo if foo = true"
s(:if,
s(:lvasgn, :foo,
s(:true)),
s(:send, nil, :foo), nil)
foo if foo = true
~~ keyword
~~~~~~~~~~~~~~~~~ expression
s(:lvasgn, :foo,
s(:true))
foo if foo = true # Line 10
~~~ name # <-- `foo` is a name
~ operator
~~~~~~~~~~ expression
s(:true)
foo if foo = true
~~~~ expression
s(:send, nil, :foo)
foo if foo = true # Line 18
~~~ selector # <-- `foo` is a selector
~~~ expression
In the edge case example, the second foo is also a variable (lines 10 and 11), but when we look at lines 18 and 19 we see the first foo has been identified as a selector (that is, a method).
This shows that it is the parser that decides whether a thing is a method or a variable and that it parses the line in a different order to how it will later be evaluated.
When the parser runs:
- it first sees the whole line as a single expression
- it then breaks it up into two expressions separated by the
ifkeyword - the first expression
foostarts with a lower case letter so it must be a method or a variable. It isn’t an existing variable and it IS NOT followed by an assignment operator so the parser concludes it must be a method - the second expression
foo = trueis broken up as expression, operator, expression. Again, the expressionfooalso starts with a lower case letter so it must be a method or a variable. It isn’t an existing variable but it IS followed by an assignment operator so the parser knows to add it to the list of local variables.
Later when the evaluator runs:
- it will first assign
truetofoo - it will then execute the conditional and check whether the result of that assignment is true (in this case it is)
- it will then call the
foomethod (which will raise aNameError, unless we handle it withmethod_missing).
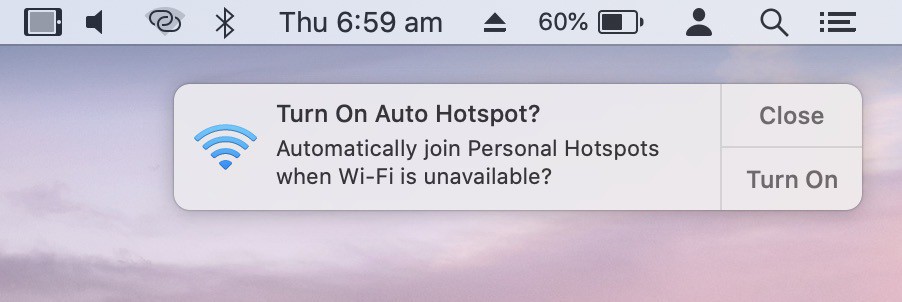
Some nice little refinements in the Apple ecosystem… macOS Catalina prompts you to join your Personal Hotspot when regular Wifi networks are unavailable… and if you say yes it asks if you want it to happen unprompted in the future.
Ruby Pop Quiz
if false
foo = 'bar'
end
foo
What will the result be?
a. foo
b. ‘bar’
c. NameError (undefined local variable or method `foo’ for main:Object)
d. ‘foo’
e. nil
f. None of the above
With my (admittedly limited) understanding of Ruby it was my intuition that the foo = 'bar' line would not get evaluated at all and therefore this would result in a NameError (option C).
I was surprised to learn that the result was actually nil. That is, the program knows foo exists but nothing is assigned to it.
With this new piece of information my intuition is now that the line is parsed but not evaluated (executed?). I’m guessing the process of parsing adds a foo node to the Abstract Syntax Tree (AST) and the presence of foo in the AST prevents the NameError I previously expected.
Now I need to figure out how to confirm that hunch… and whether it’s a good use of my time to do so ¯_(ツ)_/¯
Testing Security Controls
I’m working my way through RailsConf 2019 and I keep finding gems (excuse the pun).
No Such Thing as a Secure Application by Lyle Mullican was one such gem.
Some highlights for me were:
On Automated tests
Learning to test made me write better code… When we start to think about writing security tests we design better security controls
[Even] if you’re not testing your security controls, somebody [else] probably is… and you really don’t want to outsource security testing to the Internet
On Static Analysis
If you get false positives from a static analysis tool it might be a code smell:
If I’ve made my code hard for Brakeman to understand and reason about then I’m probably making it too hard for people to understand as well
Resilience
How well do we react to failure:
- In our app?
- Segmenting
- Limiting fall out
- In our culture?
- Blame others? Head in sand?
- Or strive to iterate and improve the security system?
Other nuggets
- Combine unit testing, static analysis, dynamic tests and manual tests for Defence in Depth
- Exploits take time… a tripwire or automated black list might be worthwhile
Will Leinweber has a lot of experience with Postgres. His RailsConf talk on what to do When it all goes Wrong (with Postgres) was very informative. I’m keen to try and learn those tools before a problem occurs!
Really thoughtful guidance on Service Objects in Ruby: katafrakt.me/2018/07/0…
Keeping them “flat” is particularly helpful. I now realise I’ve written some convoluted ones recently that probably need functionality extracted.
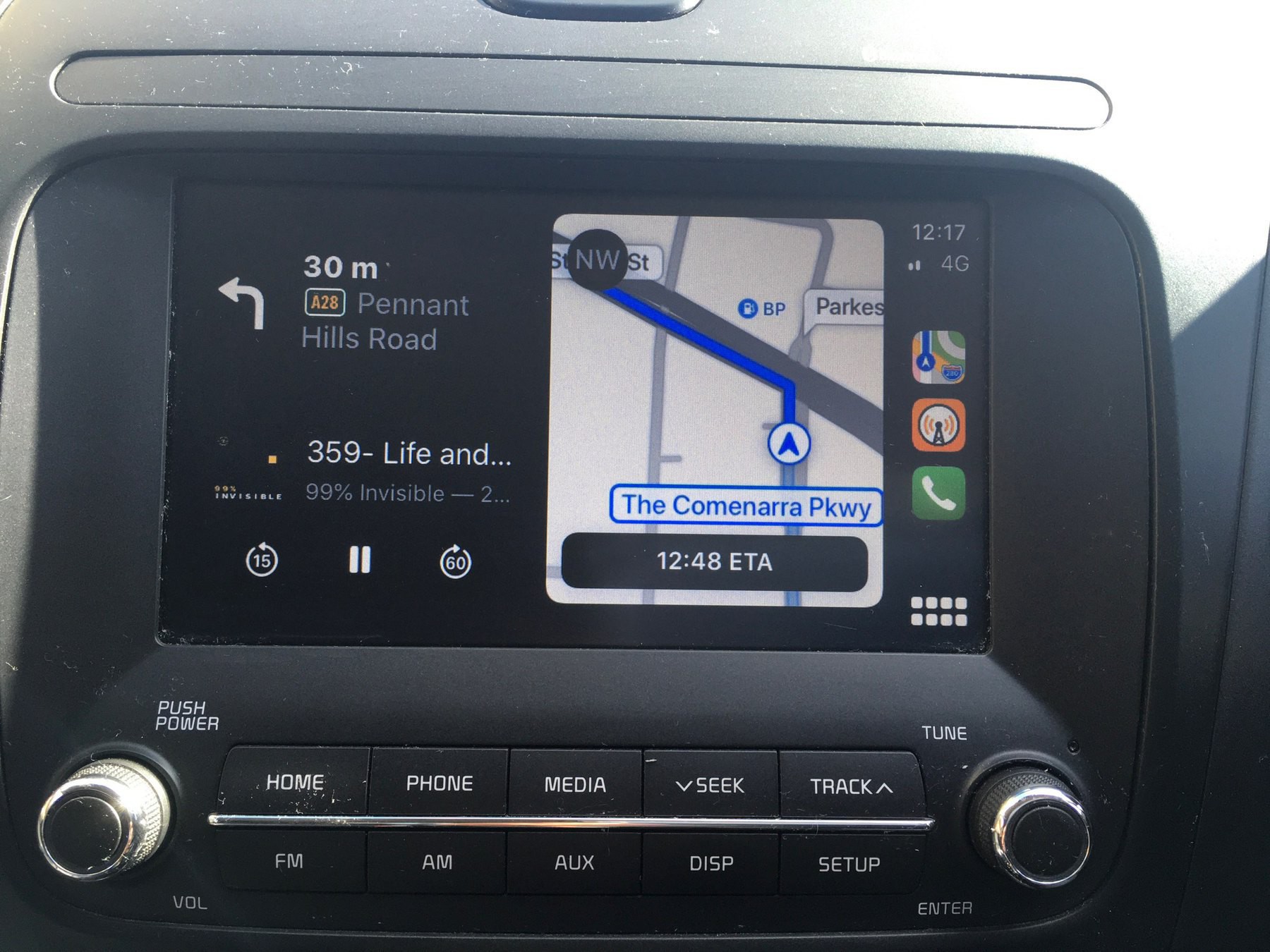
I love that, with CarPlay, my cheap car and its nasty head unit are actually a pleasure to use…
And it just got a great software upgrade when I installed the iOS 13 Public Beta!
Lots of slow but steady progress, like maps and now playing both visible at the same time!
Great presentation from RailsConf 2019 on paying down technical debt in Rails apps: youtu.be/-zIT_OEXh…
Pragmatic, well-reasoned advice coupled with clear examples of how and when to apply the techniques!
Note to future self:
assert_empty first asserts that the object under test responds to empty?, then it asserts that empty? returns true (link).
assert_not_empty (refute_empty) also uses two assertions.
If the assertions count looks too high, this could be why!
Rails, Foreign Keys and Troubleshooting
Rails’ foreign_key confuses me sometimes! I spent way too long yesterday trying to troubleshoot why a Rails relationship was only working in one direction while I was overriding the class so this post is my attempt to explain it to someone else (probably future me) in order to make sure I understand it.
Requirements
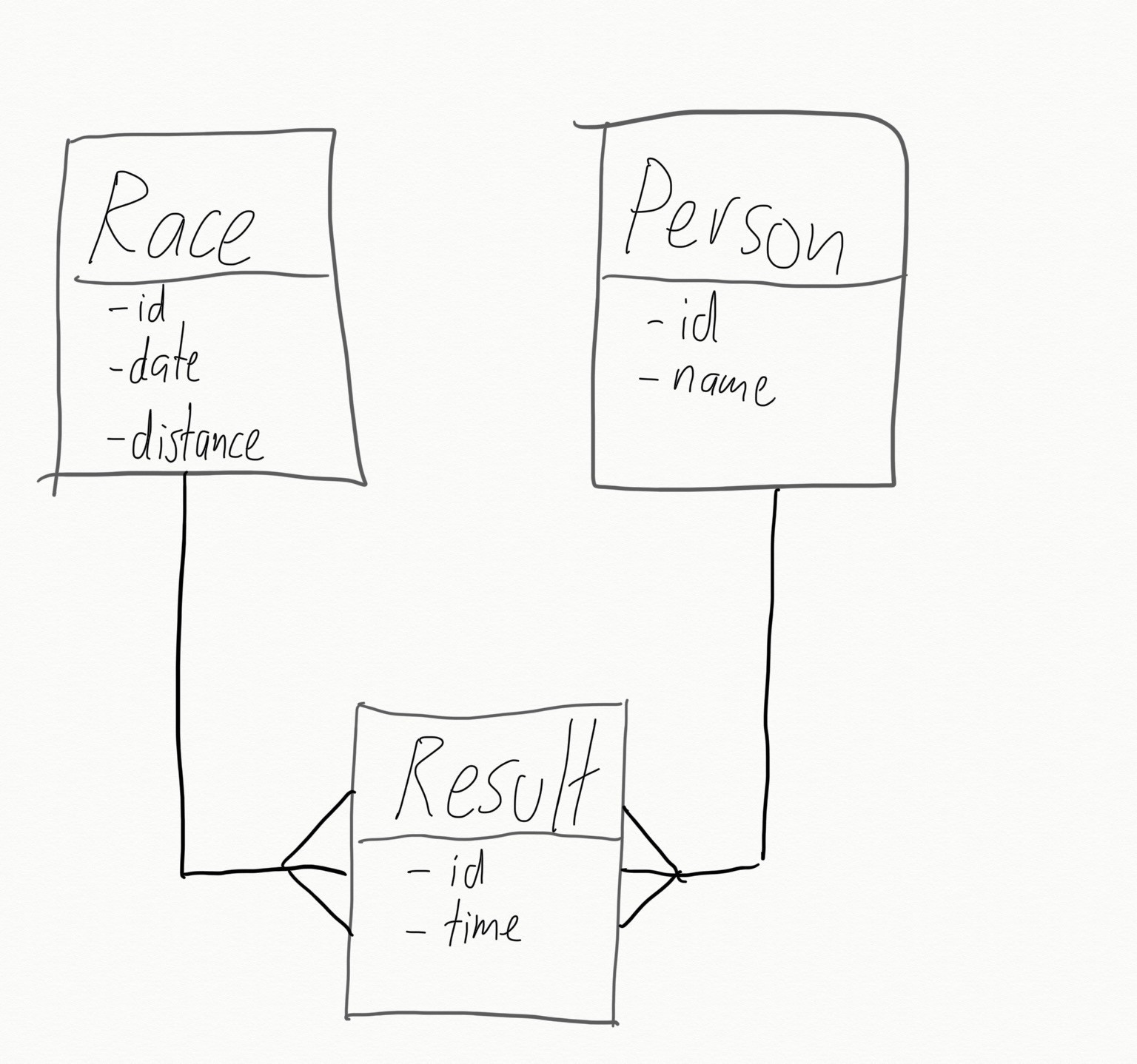
Imagine we’re trying to model the results of a running race. One way to structure it might be to have a result that belongs_to both a race and an athlete… or that a race has_many results and so does an athlete.
Further imagine that our hypothetical app already has a ‘Person’ object (and a ‘people’ table). Unless the running race is between thoroughbreds (or camels or turtles, it’s likely that our athletes are also people.
Rather than store people twice, once in an athletes table and once in a people table, lets reuse the existing table:
Solution
Generate models
The first step is to generate the new model objects. As per the requirements the ‘Person’ model already exists so we only need ‘Race’ and ‘Result’
rails g model Race date:date distance:integer
rails g model Result race:references athlete:references time:integer
By using :references as the column type in the generator, the ‘CreateResults’ migration is set up to automatically create a ‘race_id’ column (and an ‘athlete_id’ column) of the right type as well as setting null: false and foreign_key: true for both.
Migrate the Database
That’s all we need to do for races but if we try to run the migrations now with rails db:migrate the second one (‘CreateResults’) will fail. The error returned by Postgres is PG::UndefinedTable: ERROR: relation "athletes" does not exist.
This makes sense; after all there is no ‘athletes’ table. The solution is to tell ActiveRecord to use the ‘people’ table for the foreign key. This is acheived with a relatively poorly documented API option that I only found (indirectly) through Stack Overflow
After changing our create table migration from:
t.references :athlete, null: false, foreign_key: true
to:
t.references :athlete, null: false, foreign_key: { to_table: :people }
we can now successfully finish our migrations.
Add Associations
We’re getting closer now but our associations still need work. ‘Result’ kind of knows what it belongs to thanks to the generator but it does need a little help to know what class of athlete we’re dealing with here:
class Result < ApplicationRecord
belongs_to :race
belongs_to :athlete, class_name: 'Person'
# add this bit: ^^^^^^^^^^^^^^^^^^^^^^
end
Originally I specified the option foreign_key: 'athlete_id' too but this is unnecessary. The foreign key defaults to the association name (i.e. ‘athlete’) followed by ‘_id’ so specifying it adds nothing.
With ‘Result’ belonging to ‘Person’ (via ‘athlete_id’) and ‘Race’, now we just need to let them both know they have_many results:
# In race.rb add:
has_many :results
# In person.rb add:
has_many :results, foreign_key: 'athlete_id'
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^
The bit I’ve “underlined” is the key (excuse the pun 🙄). As I said earlier, originally I was specifying that exact option but on the belongs_to side, up until I finally figured out it was doing nothing over there.
The reason it belongs over on the has_many is that when we call the #results method on a Person object, the object already knows its own ID. Let’s say’s it an object called ‘matthew’ with an ID of 123. When we call matthew.results without the foreign key specified Active Record translates that to the following SQL (slightly simplified):
SELECT * FROM "results" WHERE "person_id" = 123
Without the foreign key specified, Active Record assumes that the column in the ‘results’ table will be called ‘person_id’. In our situation that causes a PG::UndefinedColumn: ERROR: column results.person_id does not exist error when we call matthew.results.
With the foreign key, Active Record knows which column in the ‘results’ table to search when looking for the id of a person:
SELECT * FROM "results" WHERE "athlete_id" = 123
It was a little bit (lot!) counter-intuitive to me that I had to tell ‘Person’ what column to use when querying another table but now I’ve written it all down it’s finally making sense to me!
But What About inverse_of?
Another thing I tried during all my troubleshooting was setting the inverse_of option on the has_many side:
# person.rb
has_many :results, inverse_of: 'athlete'
I was thinking that would help it to infer the correct column name from the class_name option on the belongs_to relation. However, I was still getting the same error I mentioned earlier:
ActiveRecord::StatementInvalid (PG::UndefinedColumn: ERROR: column results.person_id does not exist)
After reading a little more (especially this helpful article from Viget) my understanding now is that:
inverse_ofcan help prevent unnecessary database calls (e.g. if the person is already in memory when I callresult.athlete)- it’s not necessary to specify
inverse_ofon simple relationships (e.g. between ‘Race’ and ‘Results’) - if you want the aforementioned benefits, it is necessary to specify
inverse_ofwhen we provide custom association options such asclass_nameandforeign_key(i.e. like we did in our solution)
So with all that said, the final configuration I settled on was:
# app/models/person.rb
class Person < ApplicationRecord
has_many :results, foreign_key: 'athlete_id', inverse_of: :athlete
end
# app/models/race.rb
class Race < ApplicationRecord
has_many :results
end
# app/models/result.rb
class Result < ApplicationRecord
belongs_to :athlete, class_name: 'Person', inverse_of: :results
belongs_to :race
end
Final Take-away
As I was finishing up this post and trying a few things I again encountered some strange behaviour. I briefly started to have flashbacks about my hour and a half of troubleshooting and banging my head against a wall yesterday but thankfully, with my newfound understanding of how it all actually works, I was able to detach myself from the situation.
It seems that calling reload! in the Rails console wasn’t actually causing my models to be reloaded… after stopping and starting the console everything worked correctly. I’m almost certain I tried the correct configuration at some point yesterday so now I have a very strong suspicion that the same thing was happening then; that after adding in the foreign key on the has many side my attempts to reload! were unsuccessful.
It seems like there’s more I need to learn about the console and how reloading works but, considering I’m over a 1,000 words in at this point, that’s an investigation for another day!
Great interview on the Bike Shed with Eileen M. Uchitelle overcast.fm/+Duausy44…
I loved the line (around the 10 minute mark):
Frameworks are abstracted, not built!
Easing in to RuboCop seems prudent, to keep making forward progress rather than just polishing incomplete code.
For me this meant passing the --only Lint option to RuboCop so only errors and warnings get flagged (for the time being).
In Atom the steps I took were:
- install atom.io/packages/…
- install atom.io/packages/…-rubocop
tweaking the linter (via ~/.atom/config.cson)
"linter-rubocop": command: "/Users/<name>/.rbenv/shims/rubocop --only Lint"
N.B. Replace /Users/<name> with the path to your home directory. I briefly tried using a relative path to the shim (~/.rbenv/shims/rubocop) but it broke Atom.