Matthew Lindfield Seager
It looks like Anthropic’s Claude Code team has taken inspiration from Apple’s Siri team:
> Thinking a bit longer… still working on it…
Thankfully (so far), Claude Code has actually succeeded each time after that message. Siri usually fails after telling me it’s still working on it 😜
Pasting (Confluence) HTML as Markdown
Confluence does not have an export to Markdown feature. For long-term conversion I will download as .docx and convert to Markdown with Pandoc but for quick uses (e.g. copying reference documentation for an LLM) that’s overkill.
This morning I iterated with Claude on a script that works very nicely. I use an Alfred workflow to trigger it on my Mac with ⌘ ⌥ M (for Markdown) but you could just as easily trigger it with FastScripts, RayCast, Keyboard Maestro or probably even Shortcuts (or adapt it for use on Linux or Windows).
The script assumes you have Pandoc installed and that you’ve just pressed ⌘ C on some selected HTML text.
osascript -e 'the clipboard as «class HTML»' \
| perl -ne 'print chr foreach unpack("C*",pack("H*",substr($_,11,-3)))' \
| perl -pe '
s/<span class="Apple-converted-space">[^<]*<\/span>/ /g;
s/ (data-[\w-]+|style)="[^"]*"//g;
s/<span class="code"[^>]*>(.*?)<\/span>/<code>$1<\/code>/g;
' \
| pandoc -f html -t gfm --wrap=none \
| perl -pe '
s/<div[^>]*>//g;
s/<\/div>//g;
s/<[^>]+>//g;
s/^``` code-block$/```/gm;
' \
| perl -0777 -pe '
s/^[^\S\n]+$//mg;
s/\n{3,}/\n\n/g;
'
I plan to update this post as I use it more and make small tweaks. It cleans up Confluence HTML nicely but I haven’t yet tested it with other sources.
If I remember, I’ll also write another post explaining the evolution from pbpaste -Prefer rtf | pandoc -f rtf -t markdown --wrap=none (which doesn’t work) to the monstrosity above.
Today I learned that “View Source” and “Insepct Element” don’t show the same thing (checked in Safari and Chromium) 🤯
I was inspecting an element and only seeing an attribute appear once but the page source showed the attribute was set twice and the second (correct) one was being ignored!
As a hobbyist software developer, LLMs have been a game changer for my speed of development. Before Claude Code I used to start a new app every few months and then forget it a few weeks later. Now I can start and abandon multiple projects per week!
Claude PR Reviews
I wrote* my first custom command for Claude Code today, /pr-review. It’s fairly specific to a full-stack Rails app:
- common Rails code smells
- Sandi Metz’ rules to help with OOP principles
- some Stimulus guidelines inspired by Matt Swanson/Boring Rails
I’m pretty happy with the results after running it on a branch I’m about to merge but I’d love some feedback on what else I should add.
---
allowed-tools: Bash(git diff:*), Bash(git status:*), Bash(git log:*), Bash(git show:*), Bash(git remote show:*), Read, Glob, Grep, LS, Task
description: Complete a PR review of the current branch
---
You are a senior full-stack Rails engineer conducting a focused maintainability review of the changes in this branch.
GIT STATUS:
```
!`git status`
```
COMMITS:
```
!`git log --no-decorate origin/main...`
```
DIFF CONTENT:
```
!`git diff --merge-base origin/main`
```
Review the complete diff above. This contains all code changes in the PR.
OBJECTIVE:
Perform a code review to identify HIGH-CONFIDENCE anti-patterns, code smells or poor practices that will make this app harder to build and maintain. Focus on maintainability implications added by this PR.
CRITICAL INSTRUCTIONS:
1. MINIMISE FALSE POSITIVES: Only flag issues where you're confident of an anti-pattern or code smell
2. AVOID NOISE: Skip theoretical issues, style concerns, or low-impact findings
3. FOCUS ON IMPACT: Prioritise problems that make the app overly complicated or harder to maintain
CATEGORIES TO EXAMINE:
**Common Code Smells in Rails:**
- Fat models / God models
- Controller bloat
- Complex views (excessive logic in views)
- Deeply nested routes
- Overuse of callbacks
- Excessive monkey patching
- Duplicate code (outside of tests)
- Unused parameters, codepaths, routes or dependencies
**Adherence to Sandi Metz' "rules":**
1. Classes can be no longer than one hundred lines of code.
2. Methods can be no longer than five lines of code.
3. Pass no more than four parameters into a method. Hash options are parameters.
4. Controllers can instantiate only one object. Therefore, views can only know about one instance variable and views should only send messages to that object (@object.collaborator.value is not allowed).
Rule 3 does not usually apply in views where we are required to use Rails' view helpers.
**Accessibility and JavaScript Maintainability:**
- The app should mostly rely on standard Rails actions with Stimulus used for "sprinkles of interactivity". It should degrade gracefully when JavaScript is unavailable.
- Stimulus controllers should be clear, convention-driven, minimal, and reusable
- Use data-* attributes, targets, and values instead of hardcoding selectors or logic in JavaScript
- Controllers should be small: ideally <100 lines and focused on one UI concern
- JS shouldn’t duplicate business logic; just manage state, events, and DOM classes
- Use Stimulus targets, values, and classes idiomatically
- Stimulus controllers should be composable & reusable, attach multiple data-controller attributes on the same element to compose more advanced functionality
- Raw `<script>` tags in ERB views are almost always a code smell
REQUIRED OUTPUT FORMAT:
You MUST output your findings in markdown. The markdown output should contain the file, line number(s) if relevant, confidence band, description, and fix recommendation.
For example:
# Issue 1: Complex views with inline JavaScript: `app/views/foo.html.erb`
* Confidence: High
* Description: The 332-line view contains 80+ lines of inline JavaScript mixed with HTML, handling bulk actions, modals, and DOM manipulation. This violates the project guidelines requiring progressive enhancement and Stimulus controllers for JavaScript behaviour.
* Recommendation: Extract JavaScript into dedicated Stimulus controllers for bulk selection, modal handling, and export functionality. Ensure core functionality works without JavaScript following progressive enhancement principles.
CONFIDENCE SCORING:
- 0.9-1.0: Obvious problem with no plausible reason for doing it that way. Score as 'Very High'
- 0.8-0.9: Clear code smell or anti-pattern with good alternative. Score as 'High'
- 0.7-0.8: Likely code smell but may have a good reason. Score as 'Medium'
- Below 0.7: Don't report (too speculative)
FINAL REMINDER:
Focus on higher confidence findings. Better to miss some theoretical issues than flood the report with false positives. Each finding should be something a senior full stack Rails engineer would confidently raise in a PR review.
START ANALYSIS:
Begin your analysis now. Do this in 3 steps:
1. Use a sub-task to identify issues. Use the repository exploration tools to understand the codebase context, then analyse the PR changes for maintainability implications. In the prompt for this sub-task, include all of the above.
2. Then for each issue identified by the above sub-task, create a new sub-task to assess confidence and alternative patterns. Launch these sub-tasks as parallel sub-tasks. In the prompt for these sub-tasks, include everything in the "CONFIDENCE SCORING" instructions.
3. Filter out any issues where the sub-task reported a confidence less than 0.7.
Your final reply must contain the markdown report and nothing else.
*It’s heavily inspired by Anthropic’s /security-review command
Ruby date comparison
I spent way too many minutes figuring out this “active” scope is valid:
scope :active, -> { where("read_at IS NULL OR read_at > ?", 7.days.ago) }
I want ones that were read less than 7 days ago!?
The key insight is that a date that is greater than another date is “more recent than” instead of “more than”. At first I just added a comment for future me, but then I fixed it properly with a comment AND a well-named scope:
scope :unread, -> { where(read_at: nil) }
scope :read_within_past, ->(period) { where("read_at > ?", period.ago) } # '>' == 'more recent than'
scope :active, -> { unread.or(read_within_past(7.days)) }
“Unread or read within past 7 days” is something even future me with too-little sleep should be able to read and understand!
Anyone who’s had to write code to handle time and time zones (or just had to write JavaScript) can probably empathise with Claude’s plight here 😂
I’m not sure I fully understand the privacy concerns of @manton (https://www.manton.org/2025/06/05/this-court-order-is-a.html) and many others. OpenAI has been ordered to preserve data, not publish it on the open web. I don’t see a plausible path from preservation to widespread publication 🤔
Capturing the pointer in macOS screenshots
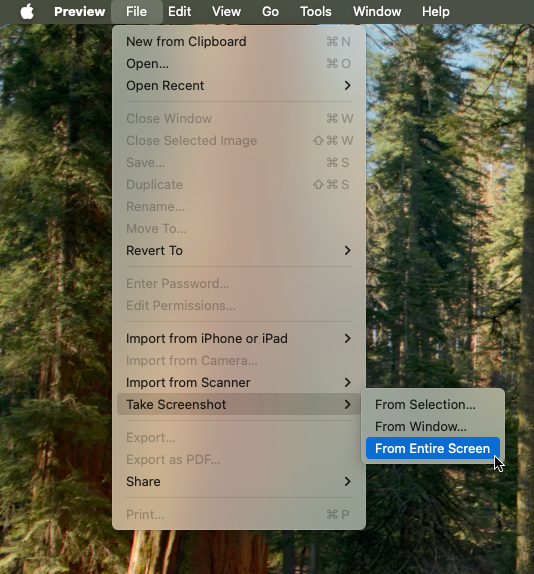
In theory you should be able to capture the mouse pointer in macOS screenshots using Command-Shift-5 → Options → Show mouse pointer (you’ll also need to add a delay to give you time to get your mouse pointer where you want it). In practice it doesn’t actually work (for me on macOS Sequoia 15.3.1).
To capture the mouse pointer without third-party software, I used Preview (which continues to surprise me): File → Take Screenshot → From Entire Screen
Note: if you have increased the mouse pointer size in accessibility, this won’t be reflected in the screenshot. To capture larger cursors you’ll need post-processing or a third-party app.
Bonus tip, for most screenshots that’s all you need… but it turns out you can’t use Preview to take screenshots of menus in Preview 🤷♂️ To take the above screenshot, I had to launch a second instance of Preview using open -n -a Preview and capture the screenshot from the second instance.
Capistrano Branches
Capistrano (as of version 3.19.1) still defaults to deploying the master branch, even though GitHub, GitLab and BitBucket have all changed their default branch name to main.
The simplest fix for this is to add a line to config/deploy.rb which sets the branch to main:
# config/deploy.rb
set :branch, "main"
You can easily override that branch setting on a per-environment basis. For example, if you want to always deploy the currently checked-out (HEAD) branch when deploying to staging, override the :branch setting in config/deploy/staging.rb. The current branch can be obtained with git rev-parse --abbrev-ref HEAD so the command becomes:
# config/deploy/staging.rb
set :branch, `git rev-parse --abbrev-ref HEAD`.chomp
Getting more granular
Setting a global default and then overriding it per-environment is probably sufficient 95+% of the time, but what if you ever want to do something different?
If it’s a one-off thing, you could edit the local copy of config/deploy.rb or config/deploy/<env>.rb and deploy. As long as you don’t commit and push the changes to Git, Capistrano on your machine will use the branch you set, and everyone else will happily keep using the original setting from Git.
However, I found a better way (on StackOverflow) that doesn’t rely on you having to remember not to commit your changes. We will set up a workflow that gives us:
- a sane default for all environments
- the ability to set a new default for a specific environment
- the ability to override the default for any given deploy (for some or all environments)
First the code, then the explanation (lightly modified from my project’s README).
# config/deploy.rb
# config valid for current version and patch releases of Capistrano
lock "~> 3.19.1"
def branch_name(default_branch)
branch = ENV.fetch('BRANCH', default_branch)
if branch == '.'
`git rev-parse --abbrev-ref HEAD`.chomp
else
branch
end
end
# Uncomment one of these to set an app-wide default for all environments
# set :branch, "main"
# set :branch, branch_name("main")
set :application, "my_app"
# etc, etc
# config/deploy/production.rb
server "<hostname>", user: "deploy", roles: %w[app db web]
set :branch, branch_name("main")
# config/deploy/staging.rb
server "<hostname>", user: "deploy", roles: %w[app db web]
set :branch, branch_name(".")
And here’s the relevant section from my project’s README.md:
Deployment
Capistrano is used for deployment. By default the main branch will be deployed in production (more info in next section), so make sure all code has been committed (and pushed), then run:
> cap production deploy
A typical deployment takes less than 30 seconds and will finish with:
00:19 deploy:log_revision
01 echo "Branch main (at a087b4c40d8ef0031a0b90773c8511d8e873fa59) deployed as release 20240921040843 b…
✔ 01 deploy@<hostname> 0.067s
The last five releases are kept on the server (in theory allowing for easy rollback) but in practice it’s generally safer to revert the changes and deploy a new release (reference).
Deploying a different branch
The default branch has been set to “main” in config/deploy/production.rb (using set :branch, branch_name("main")), but you can override it by setting the BRANCH environment variable when running Capistrano:
> BRANCH=my-new-feature cap production deploy
Set the variable to . to deploy the current branch (a bit like the current working directory on *nix systems):
> BRANCH=. cap production deploy
The . shortcut also works in deploy files. We default to using the current branch in staging using:
# config/deploy/staging.rb
set :branch, branch_name(".")
P.S. On a bigger team you might not want to make it so easy to deploy a different branch to production. In that case, don’t include the banch_name method in production.rb:
# config/deploy/production.rb
server "<hostname>", user: "deploy", roles: %w[app db web]
set :branch, "main"
P.P.S. I deliberately commented out set :branch from config/deploy.rb. That way if I forget to set the branch for a new environment, Capistrano will attempt to use master and the deploy will fail. If you want new environments to default to something else, uncomment one of the set :branch lines in config/deploy.rb
FWIW, I have a 1 year old iPhone 15 Pro Max and its battery capacity is at 98% after 261 cycles.
I too kept mine limited to 80% all year, but not rigorously like Juli Clover… I would occasionally charge mine to 100% when I knew I’d be using it a lot the next day, maybe 4 or 5 times? 🤷♂️
Saw the scary screen recording message for Microsoft Teams on macOS Sequoia but Google Meet worked fine in Safari.
Making native apps clunkier may encourage even more web apps… if so, that could lead more and more users to choose a Surface Book or Chromebook over a MacBook for their next device 🤔
Let apps link to the web?
In episode 605 of Core Intuition, @manton made a claim that past me would have completely agreed with but that I’m less convinced about today.
Because if you actually think about the stuff that the EU is finding Apple in non-compliance over, if you just look at it… Like, just let apps link to the web! This really should be uncontroversial.
— Manton Reece, starting around the 11 minute mark
I think there’s a bit more nuance to the discussion than Manton allows for here and I wonder if it’s a matter of perspective.
For instance, it used to be when I was setting up a new Mac and I saw the Analytics screen, I would think “Yes, I do want to share analytics with Manton and Daniel, Gus Mueller, Brent Simmons, Ken Case, David _Smith and all the other developers that make great Mac or iOS software”.
Now when I see that screen I think “No, I don’t want to share analytics with Google, Facebook, Taboola, casino.mindthebet.co.uk or the data brokers who trick or pay developers to bundle their SDK”.
When asked the question “Should iOS developers be allowed to link to their own website for account creation and payments?” I have a similarly bifurcated response…
On the one hand, yes, it would be great if iOS users didn’t have to jump through so many hoops to transact with trustworthy indie developers and reputable large companies.
On the other hand, there are so many bad actors out there who will exploit any opportunity to make a quick buck (or lazy ones who will bundle a sketchy SDK to avoid a bit of work). So no, I don’t want to give them additional tools to trick me into making unwanted payments or handing over my credit card details.
I know there are a bunch of kind, trustworthy, generous people on the open web (particularly among proponents of the open web!) but for every one of them it seems like there’s 10 scammers, spammers, hustlers and thieves.
I don’t know what the “right” answer is1. For all the nuance I’ve tried to include in this post, I’ve still vastly oversimplified things. And so I’ll finish with another oversimplification: Apple’s restrictions on linking out to the web benefit Apple, but I think they benefit most users just as much or more 🤷♂️
- Although I would love to know what things would be like in an alternate reality where Apple dropped their 30/15 cut to 10/5 a few years ago. [return]
Per-domain Browser for Legacy Web Apps
At work we use a legacy web app from the late 90s that doesn’t play nicely with Safari’s modern privacy practices (you may have heard of Salesforce?). Salesforce is the only website I frequently need another browser for and I always want Salesforce links to open in Brave, a fork of Chrome that I hope and assume doesn’t send all my browsing history to Google.
I previously purchased a fantastic little utility app called Bumpr getbumpr.com that lets you choose which app to use for web and mail links (including letting you use web based email to handle mailto: links).

In normal use it opens a graphical menu right near your mouse but 99% of the time I just want it to open Safari so the extra click was starting to bug me. Thankfully, there’s a super simple workaround thanks to Bumpr’s clever design (as in how it works, not just how it looks).
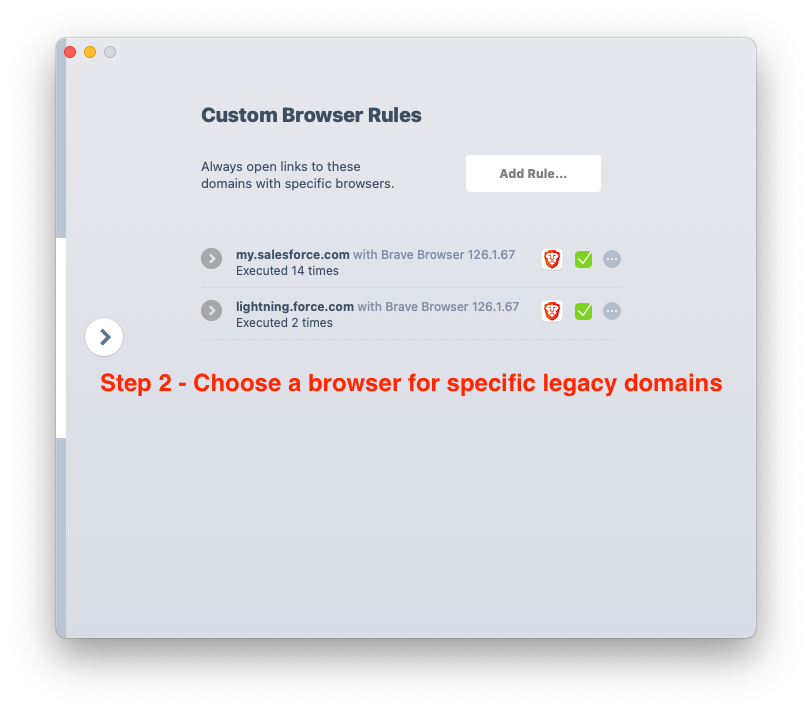
Step 1 is to remove other browsers from the Bumpr menu. If there’s only one browser listed, Bumpr will not show you a one-item menu… links will just open in that one browser without an extra click.
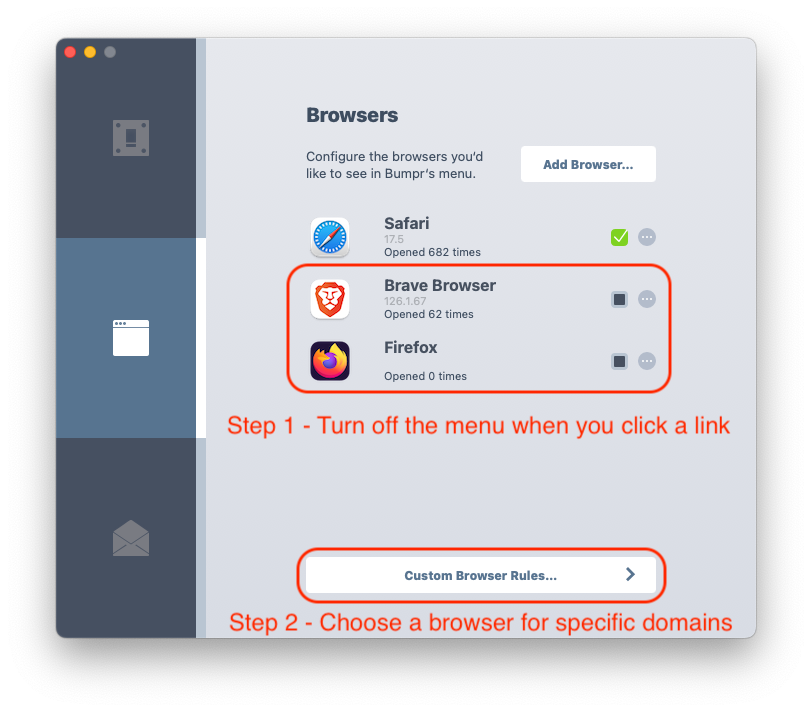
Step 2 is to add your exceptions to the “Custom Browser Rules…”. Even though step 1 removed Brave from the interactive menu, it’s still available to be used for per-domain rules so you can tell your legacy web app to always open in a more permissive browser.
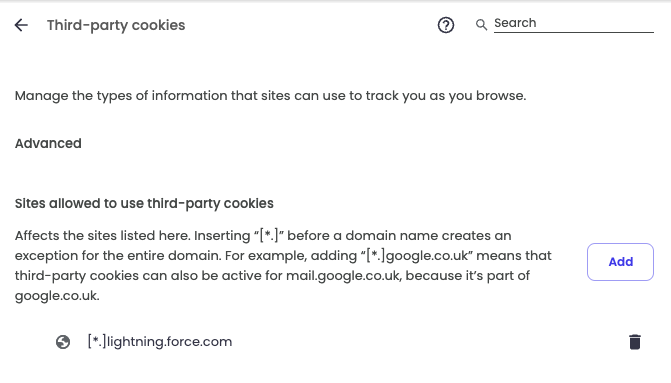
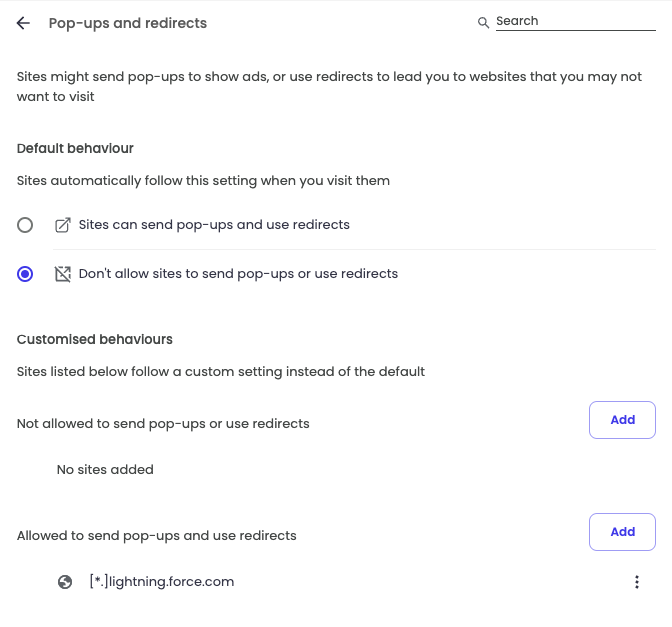
P.S. If you’re doing this specifically for Salesforce, there are some other changes you’ll probably want to make in Brave/Chrome/Edge to support Salesforce’s old fashioned design; allowing third party cookies and allowing pop ups:
Including Zeroes when Counting in SQL
TLDR: To count related records (and get a zero when there are none) use a LEFT JOIN. To count related records that match a certain criteria (and get a zero when there are none) use a CASE statement in the SELECT fields.
Longer Version
I had a table of school terms and a table of enrolments. Here’s a super simplified example using an INNER JOIN:
SELECT term.year, enrol.id
FROM term INNER JOIN enrol on term.term_id = enrol.term_id
| year | id |
|---|---|
| … | … |
| 2021 | 69423 |
| 2021 | 694170 |
| 2023 | 69423 |
| 2023 | 69584 |
| 2024 | 69456 |
To count the enrolments per year was a simple matter of adding a COUNT, changing it to a LEFT JOIN and adding the GROUP BY:
SELECT term.year, COUNT(enrol.id)
FROM term LEFT JOIN enrol on term.term_id = enrol.term_id
GROUP BY term.year
ORDER BY term.year DESC
| year | |
|---|---|
| 2024 | 1 |
| 2023 | 2 |
| 2022 | 0 |
| 2021 | 2 |
| … | … |
Note the count of 0 in 2022, that’s what I want! But then when I tried to add a WHERE clause to only get the enrolments where there was a possible flaw in the data, I stopped getting a zero count for the missing years:
SELECT term.year, COUNT(enrol.id)
FROM term LEFT JOIN enrol on term.term_id = enrol.term_id
WHERE enrol.raw_mark <> enrol.final_mark
GROUP BY term.year
ORDER BY term.year DESC
| year | |
|---|---|
| 2023 | 1 |
If I understand correctly, the WHERE clause is removing the rows (including the rows that only contain a term.year) before they get counted.
The solution (thanks to my DB guru friend TC) is to move the logic from the WHERE clause up into the SELECT. Also, now that there are blanks instead of nulls in the second column, we can go back to a regular INNER JOIN and still get the zero counts:
SELECT term.year,
COUNT(CASE WHEN enrol.raw_mark <> enrol.final_mark THEN 1 END)
FROM term INNER JOIN enrol on term.term_id = enrol.term_id
GROUP BY term.year
ORDER BY term.year DESC
| year | |
|---|---|
| 2024 | 0 |
| 2023 | 1 |
| 2022 | 0 |
| 2021 | 0 |
| … | … |
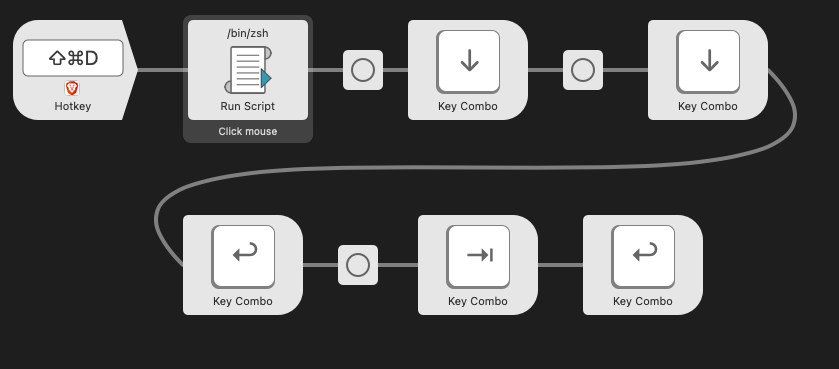
I’m using Alfred and cliclick to perform rudimentary UI automation to overcome a broken Salesforce implementation (can’t bulk delete):
- Click where the mouse is
- Press the down arrow twice (with a slight delay)
- Press enter
- Press tab
- Press enter
Moving a Micro.blog
Following Micro.blog’s pricing changes, rather than retiring an old blog hosted with a basic account, I decided to upgrade my main account to premium and migrate the old blog to the premium account. I get to access the advanced features of Micro.blog and the Micro.blog team doesn’t lose any recurring revenue, win-win!
Here’s the process I went through:
1. Logged into Micro.blog for Mac with the old account:
1. Export an archive of the blog - File → Export → Blog Archive
2. Renamed the archive from Micro.blog.bar to Micro.blog.zip and expanded it to check the contents… the only thing I could see that was missing was the Pages
3. Manually copied the text from our 2 custom Pages in Micro.Blog for Mac to a text file (ignored /archive and /photos)
4. Signed out of (“removed”) the old account from Micro.blog for Mac
2. Signed in to my old account on the web:
1. Deleted the blog
2. Changed the username on the old account (I don’t think this was necessary… later I changed it back)
3. Reset my Fediverse/Mastodon name
4. Downloaded a copy of my invoices
5. Canceled my old subscription
3. Logged in to my main account on the web:
1. Upgraded to premium
2. Added a new blog (same domain as the old one)
3. Added the two pages (only one visible in nav)
4. Deleted unwanted pages
4. Relaunched Micro.blog for Mac
1. Confirmed the new (old 😉) blog was available on the main account
2. Imported the posts and images File → Import → Blog Archive
The whole process took less than an hour (including writing this post). The slowest part was the blog import which took about 13 minutes to import 52 posts and 104 images (on a 280/20Mbps wifi connection… would have been 1/1Gbps if I’d plugged into Ethernet 🤦♂️).
My only other regret is that I didn’t think to make note of the “Design” section of the old blog… the new version looks very different and I can’t remember what theme I chose or customisations I made.
Overall, the whole process went shockingly smoothly and my only (very mild) complaint is that the Blog Archive format (or some suitable alternative) doesn’t include the pages or design info. Not being able to export and import pages might have been a bigger complaint from me if I’d had more than 2 pages to copy (or if I’d forgotten to make a manual copy before deleting the blog).
Once again I’m impressed with just how well designed and executed Micro.blog is despite being bootstrapped and being developed and supported by a very small team!
Text Replacement Pro Tips
If you’re in the Apple ecosystem1, Text Replacements are a powerful tool on Mac and iOS/iPadOS. If you’re using both, you can even sync your text replacements between all your devices via iCloud.
Here’s some tips to help you make the most of them:
- Use a character that’s usually on the iOS soft keyboard as your shortcut prefix to make typing replacements easier. I use
zorzzfor most of mine but choose what works for you - Enter your name (I have a long surname), company name, addresses or frequently used Google map links quickly:
zmls→Matthew Lindfield Seagerzacme→Acme Corporation LLC GmbH Pty Ltdzaddw→432 Cheerful Drive, Happyton NSW 2345(My mnemonic is z address work)zaddh→123 Long Avenue, Pleasantville NSW 2222(z address home)zmapw→https://maps.app.goo.gl/HYXmwHvjLGXzYvEU6(z map work)zmaph→https://maps.app.goo.gl/NtFrs1Qzn5uv1z886(z map home)
- Enter email addresses with ease e.g. replace
@@ewithmatthew.lindfieldseager@example.com. Even if you don’t have a long name like me this can still be a timesaver (I have 5 email addresses set up this way) - Type currency, unusual punctuation, keyboard shortcuts or symbols without having to look them up (or remember option key combinations on Mac):
zeuro→€,zbaht→฿, etc (or use a code likezGBP→£)zdiv→÷,zsqrt→√, etczcommand→⌘,zshift→⇧,ztab→⇥, etczsquare→□,->→→(typing that last one felt a bit meta)
- Type an emoji or emoji sequence quickly e.g. replace
zspewwith🥴🤢🤮orzlovewith🥰😍😘 - Type complex (or simple) emoticons easily e.g.
zshrugwith¯\_(ツ)_/¯ - Override autocorrect changes that you don’t like:
ta→tato be able to informally thank people (Note: The shortcut and replacement can be the same… Adding the “misspelling” to your dictionary might also help in this scenario)- Replace
;)with;)to stop autocorrect changing it to😉 - Or replace
;)with😘if you want it to use a different winking emoji - I sometimes mistype “my” as “mu” on my phone but someone has that surname in my address book so it autocorrects to “Mu” instead of “my”. I have two autocorrects to fix this;
mu→myandMutoMu.
- On that note, replacements are case sensitive so you can have different expansions for the “same” text if that makes sense to you
- Type in information without having to memorise it or look it up each time:
- Bank account details for friends to pay you back
- Meeting codes for regular Zoom/Google meetings
- Zoom passwords to take on host privileges
- Wifi passwords to share with guests
- Infrequently used phone numbers
- Business registration numbers
Bonus tips:
- Build up your replacements slowly. Next time you have to look up some often used but rarely changing information, create a text replacement and use it a few times to build up your muscle memory
- Print out a cheat-sheet for yourself or colleagues if you use lots of replacements at work
- Export/import text replacements on macOS as a
.plistfile- Back them up in case you have iCloud problems
- Share snippets with family or colleagues
- Programatically create or update snippets
- Parse the file to generate or update a cheat-sheet you can print out
- Not all text entry areas support text replacement. Here’s a workflow that might make sense sometimes (other times it will be quicker to just type it out manually) and doesn’t require you to lift your hands off the keyboard:
- bring up a text field that will work (Spotlight) with command-space
- type your shortcut (followed by space to expand it)
- press delete to remove the space you just added (optional)
- select all with command-a
- cut or copy with command-z or command-c
- escape to close Spotlight
- paste with command-v
- If you need more capabilities, investigate power user tools like Alfred, Keyboard Maestro or TextExpander.
- If you’re not (only) in the Apple ecosystem, TextExpander is cross platform and has a teams plan that lets you share snippets with your colleagues. [return]
Microsoft have really upped their game in their efforts to repulse long-time Mac users. Apparently it isn’t enough to make their apps behave like visitors from another planet, now they are calling attention to their alienness in every way they can

Took me quite a while to figure out how to access the records in a collection object returned by the restforce Gem…
It implements Ruby’s Enumerable module so you can map/collect, reject, slice, inject, etc to your heart’s content.
Seems obvious in hindsight 🤦♂️
Aussie Banks - A before and after story
Changing banks in Australia is a hassle, but here’s a before and after story that might help persuade you to make the effort to switch.
Before
Without calling them out by name, let’s just say we were with a large, national Australian bank (perhaps we can call them nAb for short 😉). We had our mortgage with them along with a savings offset account and a credit card we paid off in full each month. They were our bank from late 2013 to late 2023.
Their mobile app was reasonable and they eventually came to the party and supported Apple Pay (despite pushing hard to avoid it for a while). We didn’t love their interest rate rises or fees (see below) but we didn’t think our overall experience could be much better anywhere else, banks are banks after all.
Interest Rates
When interest rates dropped, our big bank was slow to update its mortgage rates. When interest rates rose, they were quick to update their mortgage rates and they gave us no notice. The only way to find out about rate rises was to regularly log in and check through all the transactions for a routine looking transaction with a message like “Your interest rate is w% from xx/yy/zz”. Looking back, in a period where official interest rates rose by 3.5%, our mortgage rate went up by 4.69%. When I complained about the excessive rate rises with no clear notice, they told me that according to their general terms, they only need to disclose interest rate rises in a newspaper(!!!) and on our statements (which they only issue every 6 months). Not cool.
Fees
In theory we had low-fee (maybe even fee-free) accounts but in practice we got slugged regularly. Even after they abolished the $30 fee for overdrawn accounts, they found other ways to extract their pound of flesh and keep their record profits growing:
- Purchase in USD? 3% International transaction fee (plus a poor exchange rate)
- Use an ATM overseas? $5 flat fee PLUS 3% international transaction fee (and a poor exchange rate)
- Scheduled transfer to credit card fails? $15 late payment fee (plus interest charges)
To add insult to injury, rather than send a message saying “your scheduled transfer is about to fail due to insufficient funds”, they would wait until the next day and send a message saying “your credit card payment is late”! They have the messaging infrastructure but it’s like they deliberately choose what messages to send to maximise customer fees and bank profits. 🤦♂️
After
Back in 2018 I signed up with a “neobank” called Up. They added a number of clever features over time like virtual cards, “round-ups”, savers, auto-splitting and more but when I signed up (during their closed beta) they didn’t offer joint accounts and they didn’t offer home loans. I basically only used them for their fee-free overseas transactions and for Apple Pay (until our main bank finally caved and added support in mid-2019).
Up steadily improved over the subsequent 5 years and when I took a look at them again in 2023 they had added a unique take on joint accounts (you can add a “Player 2” and have a mixture of individual and joint accounts) plus they offer a home loan with no fees and a very attractive interest rate. With those two blockers removed I checked with my wife (“Whatever makes sense to you dear”) and then took the plunge.
I sent my wife a link to join and a few minutes later I received an invite to be her “Player 2”, she had already signed up, verified her identity, opened a personal account and figured out how to invite me to open a joint account. I accepted and within seconds we had a new joint savings account and new virtual debit cards linked to that account. We then made a joint application to refinance our mortgage and the whole process was shockingly easy! It was all done online (mostly on my phone) and the only slight hiccough we encountered during the process was having to cancel our home insurance and get it re-issued in both our names.
Communication
I thought I was going to talk about rates and fees (which are both significantly better with Up) but it turns out the biggest difference I’ve noticed since we switched in October is around communication. That may sound a little nebulous but there’s been lots of little things like:
- They placed a soft hold on one of our cards due to some suspicious transactions. They sent a push notification straight away and we were able to check the transactions and lift the hold straight away. We did it all in the app and without having to talk to support
- When our home loan settled, we received a personal offer of help to understand how our home loan works and how to manage it in the app
- Advance notice of interest rate changes!!! Once a few weeks before the change and then another message on the day of the change. Not only that but they list the old AND the new rates so you can see how much they’re changing them by
- And, the thing that served as a catalyst to write this post, a push notification yesterday saying “You have a payment scheduled for tomorrow for $1,500 but there is only $700 in your account”
Thanks to the proactive communication, I don’t have to worry about sneaky rate rises, surprise fees or dodgy transactions. I can now rely on my bank to be honest, up-front and transparent. It’s a really refreshing change!
What are you waiting for?
I realise Up might not be suitable for everyone. Their offering suits us but our banking is quite straight forward. One thing that might be a deal breaker for some is that, as a neobank, they don’t have any branches. If you still deal with cash you’ll have to bank it at a post office. On the other hand, these days there’s more post offices than there are bank branches so maybe that’s not such a big deal?
They also don’t offer credit cards. For the time being we’ve kept our big bank credit card as a back-up in case we ever have problems with our Up debit cards but we haven’t used it in over a month and I suspect we’ll cancel it, probably the next time our old bank charges us an annual fee and we remember we still have it.
So, if neither of those are dealbreakers and you’re sick of your big bank, I encourage you to investigate Up (Aussies only sorry). If you decide to join, use my referral code and we will both get a $15 bonus. Or just sign up without it.
You don’t even have to go all-in straight away. I was a member for 5 years before we switched (almost) all our banking.

Enjoyed another Aussie crime novel by Chris Hammer: The Tilt 📚🎧
Well written as always and liked the way he introduced a new main character by crossing over with some supporting ones from the previous books.

Thoroughly enjoyed reading The Last Devil to Die by Richard Osman 📚

Finished Silver by Chris Hammer 🎙️📚
I’m enjoying listening to audio books while working on the house and grateful for our local library making the service available.

Finished reading: Scrublands by Chris Hammer 📚🎧