Matthew Lindfield Seager
Great presentation from RailsConf 2019 on paying down technical debt in Rails apps: youtu.be/-zIT_OEXh…
Pragmatic, well-reasoned advice coupled with clear examples of how and when to apply the techniques!
Note to future self:
assert_empty first asserts that the object under test responds to empty?, then it asserts that empty? returns true (link).
assert_not_empty (refute_empty) also uses two assertions.
If the assertions count looks too high, this could be why!
Rails, Foreign Keys and Troubleshooting
Rails’ foreign_key confuses me sometimes! I spent way too long yesterday trying to troubleshoot why a Rails relationship was only working in one direction while I was overriding the class so this post is my attempt to explain it to someone else (probably future me) in order to make sure I understand it.
Requirements
Imagine we’re trying to model the results of a running race. One way to structure it might be to have a result that belongs_to both a race and an athlete… or that a race has_many results and so does an athlete.
Further imagine that our hypothetical app already has a ‘Person’ object (and a ‘people’ table). Unless the running race is between thoroughbreds (or camels or turtles, it’s likely that our athletes are also people.
Rather than store people twice, once in an athletes table and once in a people table, lets reuse the existing table:
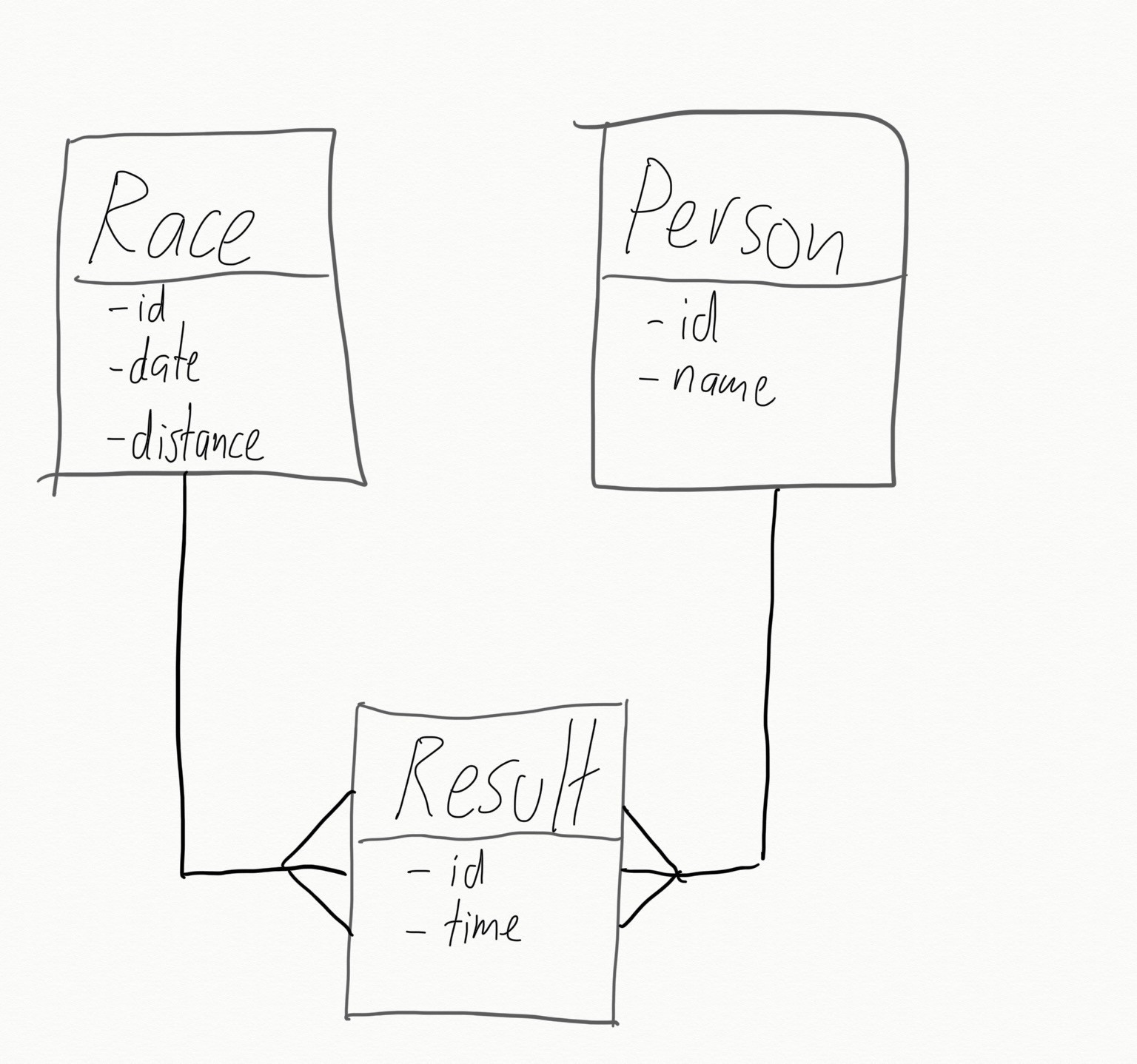
Solution
Generate models
The first step is to generate the new model objects. As per the requirements the ‘Person’ model already exists so we only need ‘Race’ and ‘Result’
rails g model Race date:date distance:integer
rails g model Result race:references athlete:references time:integer
By using :references as the column type in the generator, the ‘CreateResults’ migration is set up to automatically create a ‘race_id’ column (and an ‘athlete_id’ column) of the right type as well as setting null: false and foreign_key: true for both.
Migrate the Database
That’s all we need to do for races but if we try to run the migrations now with rails db:migrate the second one (‘CreateResults’) will fail. The error returned by Postgres is PG::UndefinedTable: ERROR: relation "athletes" does not exist.
This makes sense; after all there is no ‘athletes’ table. The solution is to tell ActiveRecord to use the ‘people’ table for the foreign key. This is acheived with a relatively poorly documented API option that I only found (indirectly) through Stack Overflow
After changing our create table migration from:
t.references :athlete, null: false, foreign_key: true
to:
t.references :athlete, null: false, foreign_key: { to_table: :people }
we can now successfully finish our migrations.
Add Associations
We’re getting closer now but our associations still need work. ‘Result’ kind of knows what it belongs to thanks to the generator but it does need a little help to know what class of athlete we’re dealing with here:
class Result < ApplicationRecord
belongs_to :race
belongs_to :athlete, class_name: 'Person'
# add this bit: ^^^^^^^^^^^^^^^^^^^^^^
end
Originally I specified the option foreign_key: 'athlete_id' too but this is unnecessary. The foreign key defaults to the association name (i.e. ‘athlete’) followed by ‘_id’ so specifying it adds nothing.
With ‘Result’ belonging to ‘Person’ (via ‘athlete_id’) and ‘Race’, now we just need to let them both know they have_many results:
# In race.rb add:
has_many :results
# In person.rb add:
has_many :results, foreign_key: 'athlete_id'
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^
The bit I’ve “underlined” is the key (excuse the pun 🙄). As I said earlier, originally I was specifying that exact option but on the belongs_to side, up until I finally figured out it was doing nothing over there.
The reason it belongs over on the has_many is that when we call the #results method on a Person object, the object already knows its own ID. Let’s say’s it an object called ‘matthew’ with an ID of 123. When we call matthew.results without the foreign key specified Active Record translates that to the following SQL (slightly simplified):
SELECT * FROM "results" WHERE "person_id" = 123
Without the foreign key specified, Active Record assumes that the column in the ‘results’ table will be called ‘person_id’. In our situation that causes a PG::UndefinedColumn: ERROR: column results.person_id does not exist error when we call matthew.results.
With the foreign key, Active Record knows which column in the ‘results’ table to search when looking for the id of a person:
SELECT * FROM "results" WHERE "athlete_id" = 123
It was a little bit (lot!) counter-intuitive to me that I had to tell ‘Person’ what column to use when querying another table but now I’ve written it all down it’s finally making sense to me!
But What About inverse_of?
Another thing I tried during all my troubleshooting was setting the inverse_of option on the has_many side:
# person.rb
has_many :results, inverse_of: 'athlete'
I was thinking that would help it to infer the correct column name from the class_name option on the belongs_to relation. However, I was still getting the same error I mentioned earlier:
ActiveRecord::StatementInvalid (PG::UndefinedColumn: ERROR: column results.person_id does not exist)
After reading a little more (especially this helpful article from Viget) my understanding now is that:
inverse_ofcan help prevent unnecessary database calls (e.g. if the person is already in memory when I callresult.athlete)- it’s not necessary to specify
inverse_ofon simple relationships (e.g. between ‘Race’ and ‘Results’) - if you want the aforementioned benefits, it is necessary to specify
inverse_ofwhen we provide custom association options such asclass_nameandforeign_key(i.e. like we did in our solution)
So with all that said, the final configuration I settled on was:
# app/models/person.rb
class Person < ApplicationRecord
has_many :results, foreign_key: 'athlete_id', inverse_of: :athlete
end
# app/models/race.rb
class Race < ApplicationRecord
has_many :results
end
# app/models/result.rb
class Result < ApplicationRecord
belongs_to :athlete, class_name: 'Person', inverse_of: :results
belongs_to :race
end
Final Take-away
As I was finishing up this post and trying a few things I again encountered some strange behaviour. I briefly started to have flashbacks about my hour and a half of troubleshooting and banging my head against a wall yesterday but thankfully, with my newfound understanding of how it all actually works, I was able to detach myself from the situation.
It seems that calling reload! in the Rails console wasn’t actually causing my models to be reloaded… after stopping and starting the console everything worked correctly. I’m almost certain I tried the correct configuration at some point yesterday so now I have a very strong suspicion that the same thing was happening then; that after adding in the foreign key on the has many side my attempts to reload! were unsuccessful.
It seems like there’s more I need to learn about the console and how reloading works but, considering I’m over a 1,000 words in at this point, that’s an investigation for another day!
Great interview on the Bike Shed with Eileen M. Uchitelle overcast.fm/+Duausy44…
I loved the line (around the 10 minute mark):
Frameworks are abstracted, not built!
Easing in to RuboCop seems prudent, to keep making forward progress rather than just polishing incomplete code.
For me this meant passing the --only Lint option to RuboCop so only errors and warnings get flagged (for the time being).
In Atom the steps I took were:
- install atom.io/packages/…
- install atom.io/packages/…-rubocop
tweaking the linter (via ~/.atom/config.cson)
"linter-rubocop": command: "/Users/<name>/.rbenv/shims/rubocop --only Lint"
N.B. Replace /Users/<name> with the path to your home directory. I briefly tried using a relative path to the shim (~/.rbenv/shims/rubocop) but it broke Atom.
I don’t trust Facebook with my address book, my social interactions, my photos or even my inane ramblings, such as these.
Maybe it’s confirmation bias but they keep proving me right!
I can’t see any future in which I trust them with my finances.

Computers are fascinating!
TIL 'a'='a ' is true in standards compliant SQL.
Turns out, if the strings are different lengths, one is padded with spaces before comparing them.
Was super confusing at first when RIGHT(Comment, 1)='; ' was finding results!
Better teardown in Minitest (than using an ensure section - www.matt17r.com/2019/06/1…) can be achieved with (wait for it!) #teardown.
You learn something new every day, sometimes two things! 🙂
UPDATE
#teardown is probably a better way of achieving the desired outcome
MiniTest allows ensure blocks, even with Rails syntax 🎉
I already knew Ruby methods (and classes) could have ensure blocks:
def some_method
do_something_that_might_blow_up
ensure
tidy_up_regardless
end
…and I knew MiniTest tests are just standard ruby methods:
def test_some_functionality
assert true
end
…but I wasn’t sure if the two worked together using Rails’ test macro that lets you write nicer test names:
test "the truth" do
assert true
end
After spending some too much time trying to find an answer I eventually realised I should just try it out and see:
test 'the truth' do
assert true
raise StandardError
ensure
refute false
puts 'Clean up!'
end
And it worked! I see ‘Clean up!’ in the console and both assertions get called (in addition to the error being raised):
1 tests, 2 assertions, 0 failures, 1 errors, 0 skips
OpenStructs are SLOW, at least according to an article from a few years ago - palexander.posthaven.com/ruby-data…
I can’t vouch for how realistic the test is but running it again today as is shows that hashes have improved significantly. They are now faster than classes and ONE HUNDRED times faster than OpenStructs in this scenario.
user system total real
hash: 1.066739 0.005513 1.072252 ( 1.098668)
openstruct: 107.167921 0.261942 107.429863 (107.722112)
struct: 2.185639 0.002021 2.187660 ( 2.191069)
class: 1.710577 0.001941 1.712518 ( 1.715534)
Don’t prematurely optimise but if you’re doing anything that involves a lot of OpenStruct creation (which is where the overhead lies) it might be best to choose a different data structure.
On a related note, I’m struggling to figure out when passing around a loosely defined OpenStruct would ever be preferable to a class. Seems like an OpenStruct would unnecessarily couple the creator and the consumer.
More academically, I also re-ran the other benchmark, this time increasing the count to 100,000,000 and adding in a method that used positional arguments.
user system total real
keywords: 23.196255 0.054049 23.250304 ( 23.366176)
positional: 19.664959 0.044322 19.709281 ( 19.789321)
hash: 31.235545 0.039376 31.274921 ( 31.328692)
In this case I was gratified to see that keyword arguments are only slightly slower than positional ones. I much prefer keyword arguments as they are clearly defined in the method signature, raise helpful ArgumentErrors when you leave them out or type them wrong and are much easier to reason about when reading code where the method gets called.
Postgres tip:
ALTER DEFAULT PRIVILEGES only applies the specified privileges to objects created by the role specified by FOR USER (or the role who ran the ALTER statement if no user specified)
Life tip:
Stack Overflow community is awesome! Great resource for sharing knowledge!
Automating Minitest in Rails 6
I’m building a new app in Rails 6 (6.0.0.rc1) and while I use RSpec at work I’ve been enjoying using Minitest in my hobby projects.
I’d love to know if there’s ways to improve my setup but here’s how I set up my app to run Minitest tests automatically with Guard (https://github.com/guard/guard)
Set Up
Install the necessary gems in the
:developmentgroup in ‘Gemfile’ and runbundle. While we’re at it lets give our minitest results a makeover withminitest-reporters:# Gemfile group :development do ... gem 'guard' gem 'guard-minitest' end group :test do ... gem 'minitest-reporters' end- Finish the makeover by adding a few configuration tweaks into our test helper:
# test/test_helper.rb require 'rails/test_help' # existing line... require 'minitest/reporters' Minitest::Reporters.use!( Minitest::Reporters::ProgressReporter.new(color: true), ENV, Minitest.backtrace_filter )- Finish the makeover by adding a few configuration tweaks into our test helper:
Set up a Guardfile to watch certain files and folders. Originally I used
bundle exec guard init minitestbut I ended up deleting/rewriting most of the file:# Guardfile guard :minitest do # Run everything within 'test' if the test helper changes watch(%r{^test/test_helper\.rb$}) { 'test' } # Run everything within 'test/system' if ApplicationSystemTestCase changes watch(%r{^test/application_system_test_case\.rb$}) { 'test/system' } # Run the corresponding test anytime something within 'app' changes # e.g. 'app/models/example.rb' => 'test/models/example_test.rb' watch(%r{^app/(.+)\.rb$}) { |m| "test/#{m[1]}_test.rb" } # Run a test any time it changes watch(%r{^test/.+_test\.rb$}) # Run everything in or below 'test/controllers' everytime # ApplicationController changes # watch(%r{^app/controllers/application_controller\.rb$}) do # 'test/controllers' # end # Run integration test every time a corresponding controller changes # watch(%r{^app/controllers/(.+)_controller\.rb$}) do |m| # "test/integration/#{m[1]}_test.rb" # end # Run mailer tests when mailer views change # watch(%r{^app/views/(.+)_mailer/.+}) do |m| # "test/mailers/#{m[1]}_mailer_test.rb" # end end- Add relevant testing information to the README. I added the recommended approach (using
bundle exec guardto automate the running of tests) but also included information on how to run tests individually or in groups. - Commit all the changes to Git with a meaningful commit message (i.e. less what, more why)
Caveats
- At the time of writing ‘guard-minitest’ (https://github.com/guard/guard-minitest) has not been updated for 18 months. It’s likely it’s complete and stable but it may not be getting the attention it deserves… even just a minor Rails 6 update to the template would be a good sign.
- I’ve commented out the controller and integration tests in my Guardfile because I don’t have any of those (yet?). I’m still finding my way but I like the idea of testing all the bits and pieces in isolation and then just having a smallish number of System tests that exercise the major functionality.
- The minitest-reporters gem and associated configuration are both optional. I just like a simple display with a splash of colour to easily see Red vs Green test states.
- Add relevant testing information to the README. I added the recommended approach (using
I dislike the “vote for your desired feature” approach to product development. It seems like a cop out to me (especially on smaller products).
Rather than doing the hard but necessary work of understanding (and anticipating!) customer needs the task gets farmed out to the crowd.
Enjoyed seeing Aladdin at the drive-in tonight! Weather held off, we had a lovely picnic dinner with friends, the movie was fun and our car started again 🙂
Only downside was lack of volume… wonder if it’s related to low transmission power (to keep signal hyper local)? 🤔
I deployed a new Rails app to Heroku tonight.
It’s so ridiculously easy, especially now I’ve done it once or twice and have everything installed.
I’m very ~tight~ fiscally conservative though, so I’ll have to wait and see if I’m still happy once I’m off the free dynos 🤑
Today I learned SQL Server’s default encoding automatically equates similar characters to each other for sorting/searching. Normally that’s a good thing (e.g. so c and ç sort the same way) but today I wanted to find a specific unicode character…
I needed to find (and replace) all “Narrow Non-Break Space” characters but searching for LIKE '%' + NCHAR(8239) + '%' was also finding ordinary spaces.
The answer was to tell it to use a binary comparison when evaluating that field with COLLATE Latin1_General_BIN:
SELECT *
FROM Comments
WHERE Comment COLLATE Latin1_General_BIN LIKE '%' + NCHAR(8239) + '%'
to find them and:
UPDATE Comments
SET Comment = REPLACE(
Comment COLLATE Latin1_General_BIN,
NCHAR(8239) COLLATE Latin1_General_BIN,
' '
)
to replace them with regular spaces.
Priority Notifications is a new Teams feature. It allows a user to mark a chat message in Teams as “Urgent”. Urgent Messages notify users repeatedly for a period of 20 minutes or until messages are picked up and read by the recipient
Such a user hostile feature. Do not want!
Yesterday I posted about the one benefit of GraphQL I actually want… www.matt17r.com/2019/06/1…
This clip is the particular snippet of the conversation I was referring to
GraphQL vs(?) REST
I’ve been coming across a lot of GraphQL listenings/readings lately. Below is a small sampling and my very brief impressions.
The fourth link is the one that excites me most (spoiler, it’s not actually GraphQL).
- Recent episode(s) of The Bikeshed, particularly episode 198 (and even more particularly, 1 minute starting at 15:24): I really like the idea of GraphQL helping them to ask the right questions - questions about business processes rather than just data flow and endpoints
- Ruby on Rails 273 with Shawnee Gao from Square: Interesting use case but not really applicable in my situation
- Evil Martians tutorial/blog post: Wow! That’s only part 1 and it already looks like a lot of work!!! And of the three benefits they mention (not overfetching, being strongly typed and schema introspection) the last two seem to come with pluses and minuses of their own
- Remote Ruby with Lee Richmond from Bloomberg: Best of both worlds!?!? According to Lee, Graphiti offers GraphQL-like fetching but with a Rails-like RESTful approach that brings sensible, predictable conventions to API design.
Based on that last link I’m VERY keen to try out Graphiti (and friends):
- Why Graphiti?
- Intro video on YouTube
- Quickstart tutorial so you can take it for a spin yourself
I’m curious to know if Graphiti can offer the same benefit Chris Toomey mentioned that GraphQL offers of encouraging them to ask the right questions.
Fully Facebook Free (Finally)
I just deleted my WhatsApp account despite it being the best (only) way to get information from some groups.
Having previosuly deleted my Instagram account (and not having had a Facebook account for several years now) I think I’m finally 100% Facebook free.
I don’t trust Facebook with my personal data and it doesn’t get much more personal than my address book. Not only does it contain the names of everyone I know (or used to know), but for many of them it includes their birthdate, phone number(s), email address(es), home or work address and more.
For a while I tried to compromise by turning off access to my Contacts for WhatsApp but it wouldn’t let me start a new message thread with that off, not even by typing in the phone number manually.
I’m under no illusion that Facebook already has all that information and more (from other people’s address books) and I know they maintain shadow profiles on people who don’t have an active Facebook profile but I refuse to willingly give them that information myself.
Keen to watch the RubyConf 2019 talks!
https://www.youtube.com/playlist?list=PLE7tQUdRKcyaOq3HlRm9h_Q_WhWKqm5xc
Just need to find a spare 40-50 hours 😆
I’ll be interested to see how “Sign In With Apple” develops.
One of the key complaints about Apple in schools is that they don’t have an identity management story. Every school uses G Suite, O365/AD, or both for identity.
Maybe one day SIWA will have an edu variant???
PSA: Having a Single Source of Truth is not about consolidating every bit of data in one enormous system.
Make sure “every data element is stored exactly once” (https://en.wikipedia.org/wiki/Single_source_of_truth) but each element should live in the system that makes most sense.